

Son muchos los cambios a nivel social que traerán los coches autónomos. Uno de ellos, de múltiples aristas, tiene que ver con el uso del espacio dentro del vehículo. Un trabajo publicado en la revista Annals of Tourism Research, que se dedica a estudiar el turismo desde una perspectiva académica, aborda este aspecto de los coches autónomos. (more…)
Author: admin
-

Progresos del almacenamiento de energía solar en fluidos
Los colectores solares a menudo acumulan durante el día y en verano más energía de la que se necesita. De noche y en invierno ocurre al revés. Por eso se está investigando intensamente en tecnologías de almacenamiento del calor o de la corriente eléctrica que no sean costosas, que tengan pocas pérdidas y que duren largo tiempo. (more…)
-
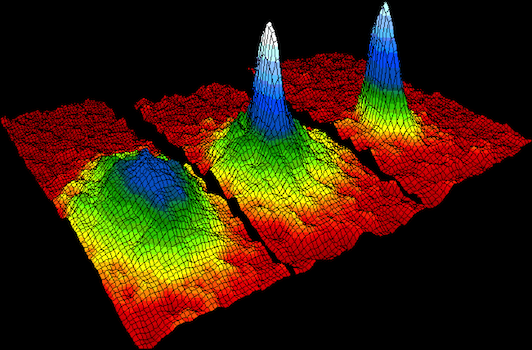
Científicos de la UNAM obtienen condensado de Bose-Einstein
En el Laboratorio de Materia Ultrafría del Instituto de Física de la Universidad Nacional Autónoma de México (UNAM), un grupo de científicos logró bajar la temperatura de un gas a tan solo 20 mil millonésimas —0.00000002— por encima del cero absoluto — -273.15 °C —, es decir, produjeron el primer condensado de Bose-Einstein en México. (more…)
-

El WC de Bill Gates, sin agua ni desagües, y transforma las heces en fertilizante
Puede ser una verdadera revolución en los países donde la población no tiene acceso a instalaciones sanitarias seguras. Con el apoyo de la Fundación Bill y Melinda Gates, se ha desarrollado una nueva solución a este problema. Un baño, muy especial, que no necesita agua o desagüe y que transforma la basura humana en fertilizante. (more…)
-

China vuelve a prohibir la venta de huesos de tigre y cuernos de rinoceronte tras la furia internacional
¡Buenas noticias desde China! Tras una intensa reacción internacional, el gobierno chino anunció el lunes que ha pospuesto la regulación que habría permitido el uso de huesos de tigre y cuernos de rinoceronte en la medicina, investigación y otros fines. (more…)
-

Presentan una brújula cuántica para la navegación precisa sin satélites
Un acelerómetro cuántico, que funciona como un sistema autónomo de navegación que no se basa en ninguna señal externa, ha sido presentado por científicos del Imperial College London y M Squared. (more…)
-

Tu cuenta de Facebook nunca fue segura: estas son todas las vulnerabilidades de la red social
Hace tiempo que Facebook dejó de ser la red social favorita de los usuarios. Nadie le niega su potencial de alcance (más de 2.000 millones de usuarios) y que diez años después siga siendo la red social masiva en todo el mundo, pero no nos dejemos engañar por las cifras: la plataforma cada vez tiene más usuarios zombis y menos adeptos, ya que la mayoría encuentra mucho más atractivas otras redes sociales como Instagram y Twitter u otras aplicaciones de mensajería instantánea como Whatsapp. (more…)
-

SORBOS, la alternativa biodegradable y comestible a las pajitas de plástico
Las llamamos pajitas de plástico, cañitas o sorbetes y son parte de nuestra vida cotidiana. Están en todas partes actualmente y se usan para todas las bebidas que encontramos en diferentes establecimientos, desde cafés hasta bebidas alcohólicas en un bar. Esa frecuencia de uso se debe a que son accesorios muy cómodos de usar, desechables, que usamos una sola vez, pero lamentablemente, eso le hace un gran daño al planeta. (more…)
-

¿Desconexión digital? Lo que sobran son los horarios
La Ley de Protección de Datos que se está tramitando en las Cortes Generales recoge el derecho a la desconexión digital de los trabajadores. ¿El objetivo? Garantizar que el tiempo de descanso, permisos y vacaciones se respete para potenciar la conciliación de la vida laboral, personal y familiar. Pero, ¿es esta desconexión digital ventajosa para todos los empleados? (more…)
-
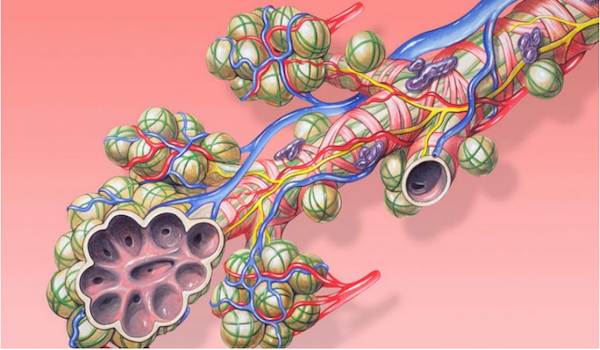
Investiga científica mexicana en Alemania vías de regeneración de tejido pulmonar y obtiene reconocimientos internacionales
El interés por encontrar mecanismos que ayuden a la regeneración de células pulmonares, así como para hacer frente a las enfermedades que aquejan a ese órgano, llevó a la científica mexicana Ana Ivonne Vázquez Armendariz a realizar una línea de investigación en la Universidad Justus Liebig en Giessen, Alemania. (more…)