

Justo cuando pensaba que no podía crecer de manera más explosiva, el panorama de datos / IA simplemente lo hizo: el rápido ritmo de creación de la empresa, el lanzamiento de nuevos productos y proyectos emocionantes, una avalancha de financiamientos de capital de riesgo , creación de unicornios, OPI, etc.
También ha sido un año de múltiples hilos e historias entrelazados.
Una historia ha sido la maduración del ecosistema, con los líderes del mercado alcanzando una gran escala y aumentando sus ambiciones de dominar el mercado global, en particular a través de ofertas de productos cada vez más amplias. Algunas de esas empresas, como Snowflake, han prosperado en los mercados públicos (consulte nuestro índice de empresas públicas MAD ), y otras (Databricks, Dataiku, DataRobot, etc.) han recaudado grandes cantidades ( o en el caso de Databricks), gigantes ) rondas en valoraciones multimillonarias y están llamando a la puerta de la OPI (consulte nuestro Índice de empresas emergentes MAD ).
Pero en el otro extremo del espectro, este año también ha visto la rápida aparición de una nueva generación de datos y nuevas empresas de aprendizaje automático . Ya sea que se fundaron hace unos años o unos meses, muchos experimentaron un crecimiento acelerado en el último año. En parte se debe a un entorno rabioso de financiación de capital riesgo y parte, más fundamentalmente, se debe a los puntos de inflexión del mercado.
El año pasado, hubo menos discusiones que acapararon los titulares sobre las aplicaciones futuristas de la IA (vehículos autónomos, etc.) y, como resultado, un poco menos de exageración de la IA. Independientemente, las empresas de aplicaciones basadas en datos y ML / AI han seguido prosperando, en particular aquellas que se centran en casos de tendencias de uso empresarial. Mientras tanto, gran parte de la acción ha estado sucediendo detrás de escena en el lado de la infraestructura de datos y ML, con categorías completamente nuevas (observabilidad de datos, ETL inverso, tiendas de métricas, etc.) que aparecen o se aceleran drásticamente .
Para realizar un seguimiento de esta evolución, este es nuestro octavo panorama anual y el “estado de unión” del ecosistema de datos e inteligencia artificial, en coautoría este año con mi colega de FirstMark, John Wu . (Para cualquier persona interesada, aquí están las versiones anteriores: 2012 , 2014 , 2016 , 2017 , 2018 , 2019: Parte I y Parte II , y 2020 ).
Para aquellos que han comentado a lo largo de los años lo increíblemente ocupado que está el gráfico, les encantará nuestro nuevo acrónimo: aprendizaje automático, inteligencia artificial y datos (MAD): ¡este es ahora oficialmente el panorama MAD!
A lo largo de los años, hemos aprendido que esas publicaciones son leídas por un grupo amplio de personas, por lo que hemos intentado proporcionar un poco para todos: una vista macro que, con suerte, será interesante y accesible para la mayoría, y luego un poco más granular. descripción general de las tendencias en la infraestructura de datos y ML / AI para personas con un mayor conocimiento de la industria.
Notas rápidas:
- Mi colega John y yo somos capital de riesgo en etapa inicial en FirstMark e invertimos de manera muy activa en el espacio de datos / IA. Las empresas de nuestra cartera están señaladas con un (*) en este artículo.
Vamos a profundizar en.
La vista macro: dar sentido a la complejidad del ecosistema
Comencemos con una visión de alto nivel del mercado. Dado que el número de empresas en el espacio sigue cada año, las preguntas inevitables son: ¿Por qué está sucediendo esto? ¿Cuánto tiempo puede continuar? ¿Pasará la industria por una ola de consolidación?
Rebobinar: la megatendencia
Los lectores de versiones anteriores de este panorama sabrán que somos implacablemente optimistas sobre el ecosistema de datos e inteligencia artificial.
Como dijimos en años anteriores, la tendencia fundamental es que cada empresa se esté convirtiendo no solo en una empresa de software, sino también en una empresa de datos.
Históricamente, y todavía hoy en muchas organizaciones, los datos han significado datos transaccionales almacenados en bases de datos relacionales y quizás algunos paneles de control para el análisis básico de lo que le sucedió a la empresa en los últimos meses.
Pero las empresas ahora están avanzando hacia un mundo donde los datos y la inteligencia artificial están integrados en innumerables procesos internos y aplicaciones externas, tanto con fines analíticos como operativos. Este es el comienzo de la era de la empresa inteligente y automatizada, donde las métricas de la empresa están disponibles en tiempo real , las solicitudes de hipotecas se procesan automáticamente, los chatbots de IA brindan soporte al cliente las 24 horas del día, los 7 días de la semana, se predice la deserción, las amenazas cibernéticas se detectan en tiempo real, y las cadenas de suministro se ajustan automáticamente a las fluctuaciones de la demanda.
Esta evolución fundamental ha sido impulsada por avances dramáticos en la tecnología subyacente, en particular, una relación simbiótica entre la infraestructura de datos, por un lado, y el aprendizaje automático y la IA, por el otro.
Ambas áreas han tenido su propia historia y distritos electorales separados, pero han operado cada vez más al unísono en los últimos años. La primera ola de innovación fue la era del “Big Data”, a principios de la década de 2010, donde la innovación se centró en la creación de tecnologías para aprovechar las enormes cantidades de datos digitales que se crean todos los días. Luego, resultó que si aplicaba big data a algunos algoritmos de inteligencia artificial de una década (aprendizaje profundo), obtenía resultados sorprendentes y eso desencadenó toda la ola actual de entusiasmo en torno a la inteligencia artificial. A su vez, la IA se convirtió en un motor importante para el desarrollo de la infraestructura de datos: si podemos construir todas esas aplicaciones con IA, entonces necesitaremos una mejor infraestructura de datos, y así sucesivamente.
Avance rápido hasta 2021: los términos en sí mismos (big data, IA, etc.) han experimentado los altibajos del ciclo de la publicidad, y hoy se escuchan muchas conversaciones sobre la automatización, pero fundamentalmente se trata de la misma megatendencia.
El gran desbloqueo
Gran parte de la aceleración actual en el espacio de datos / IA se puede rastrear hasta el auge de los almacenes de datos en la nube (y sus primos Lakehouse , más sobre esto más adelante) en los últimos años.
Es irónico porque los almacenes de datos abordan una de las necesidades más básicas, peatonales, pero también fundamentales en la infraestructura de datos: ¿Dónde se almacena todo? El almacenamiento y el procesamiento se encuentran en la parte inferior de la “jerarquía de necesidades” de datos / IA; consulte la famosa publicación del blog de Monica Rogati aquí , es decir, lo que necesita tener antes de poder hacer cosas más sofisticadas como análisis e IA.
Se imaginaría que después de más de 15 años de la revolución de los macrodatos, esa necesidad se había resuelto hace mucho tiempo, pero no fue así.
En retrospectiva, el éxito inicial de Hadoop fue un poco falso para el espacio: Hadoop, la tecnología de big data de OG, intentó resolver la capa de almacenamiento y procesamiento. Desempeñó un papel realmente importante en términos de transmitir la idea de que se podía extraer valor real de cantidades masivas de datos, pero su complejidad técnica general limitó en última instancia su aplicabilidad a un pequeño grupo de empresas, y nunca logró realmente la penetración de mercado que incluso los almacenes de datos más antiguos (por ejemplo, Vertica) lo tenían hace algunas décadas.
Hoy en día, los almacenes de datos en la nube (Snowflake, Amazon Redshift y Google BigQuery) y los lakehouses (Databricks) brindan la capacidad de almacenar cantidades masivas de datos de una manera que es útil, que no tiene costos prohibitivos y no requiere un ejército de personal técnico para mantener. En otras palabras, después de todos estos años, ahora finalmente es posible almacenar y procesar big data.
Eso es un gran problema y ha demostrado ser un gran desbloqueo para el resto del espacio de datos / IA, por varias razones.
Primero, el aumento de los almacenes de datos aumenta considerablemente el tamaño del mercado no solo para su categoría, sino para todo el ecosistema de datos e inteligencia artificial. Debido a su facilidad de uso y precios basados en el consumo (en los que paga sobre la marcha), los almacenes de datos se convierten en la puerta de entrada para que todas las empresas se conviertan en empresas de datos. Ya sea que sea una empresa de Global 2000 o una startup en etapa inicial, ahora puede comenzar a construir su infraestructura de datos central con un mínimo de molestias. (Incluso FirstMark, una empresa de riesgo con varios miles de millones bajo administración y 20 miembros del equipo, tiene su propia instancia de Snowflake).
En segundo lugar, los almacenes de datos han desbloqueado todo un ecosistema de herramientas y empresas que giran en torno a ellos: ETL, ELT, ETL inverso, herramientas de calidad de datos centradas en el almacén, almacenes de métricas, análisis aumentado, etc. Muchos se refieren a este ecosistema como los “datos modernos stack ”(que discutimos en nuestro panorama 2020 ). Varios fundadores vieron el surgimiento de la pila de datos moderna como una oportunidad para lanzar nuevas empresas, y no es de extrañar que gran parte de la actividad de financiación de VC febril durante el último año se haya centrado en las empresas de pila de datos modernas. Las empresas emergentes que fueron las primeras en la tendencia (y desempeñaron un papel fundamental en la definición del concepto) ahora están alcanzando la escala, incluido DBT Labs, un proveedor de herramientas de transformación para ingenieros analíticos (consulte nuestraFireside Chat con Tristan Handy, CEO de DBT Labs y Jeremiah Lowin, CEO de Prefect ), y Fivetran, un proveedor de soluciones de integración de datos automatizadas que transmite datos a los almacenes de datos (consulte nuestro Fireside Chat con George Fraser, CEO de Fivetran ), ambos de los cuales recaudaron grandes rondas recientemente (ver sección de Financiamiento).
En tercer lugar, debido a que resuelven la capa de almacenamiento fundamental, los almacenes de datos liberan a las empresas para que comiencen a centrarse en proyectos de alto valor que aparecen más arriba en la jerarquía de necesidades de datos. Ahora que tiene sus datos almacenados, es más fácil concentrarse seriamente en otras cosas como el procesamiento en tiempo real, la analítica aumentada o el aprendizaje automático. Esto, a su vez, aumenta la demanda del mercado de todo tipo de otros datos y herramientas y plataformas de inteligencia artificial. Se crea un volante donde una mayor demanda de los clientes crea más innovación a partir de las empresas de infraestructura de datos y ML.
Dado que tienen un impacto tan directo e indirecto en el espacio, los almacenes de datos son un referente importante para toda la industria de datos; a medida que crecen, también lo hace el resto del espacio.
La buena noticia para la industria de los datos y la inteligencia artificial es que los almacenes de datos y los almacenes de lagos están creciendo muy rápido, a escala. Snowflake, por ejemplo, mostró un crecimiento interanual del 103% en sus resultados del segundo trimestre más recientes, con una increíble retención de ingresos netos del 169% (lo que significa que los clientes existentes siguen usando y pagando Snowflake cada vez más a lo largo del tiempo). Snowflake tiene como objetivo $ 10 mil millones en ingresos para 2028. Existe una posibilidad real de que lleguen antes. Curiosamente, con precios basados en el consumo donde los ingresos comienzan a fluir solo después de que el producto está completamente implementado, la tracción actual de los clientes de la compañía podría estar muy por delante de sus cifras de ingresos más recientes.
Sin duda, esto podría ser solo el comienzo de cómo podrían convertirse los grandes almacenes de datos. Algunos observadores creen que los almacenes de datos y los almacenes de lagos, en conjunto, podrían llegar al 100% de penetración del mercado con el tiempo (es decir, cada empresa relevante tiene uno), de una manera que nunca fue cierta para las tecnologías de datos anteriores como los almacenes de datos tradicionales como Vertica (también caro y engorroso de implementar) y Hadoop (demasiado experimental y técnico).
Si bien esto no significa que todos los proveedores de almacenes de datos y todas las nuevas empresas de datos, o incluso un segmento de mercado, tendrán éxito, direccionalmente esto es un augurio increíblemente bueno para la industria de datos / IA en su conjunto.
El impacto titánico: Snowflake vs.Databricks
Snowflake ha sido el ejemplo del espacio de datos recientemente. Su oferta pública inicial en septiembre de 2020 fue la oferta pública inicial de software más grande de la historia (lo habíamos cubierto en ese momento en nuestro Quick S-1 Teardown: Snowflake ). En el momento de escribir este artículo, y después de algunos altibajos, es una empresa pública con capitalización de mercado de $ 95 mil millones.
Sin embargo, Databricks se perfila ahora como un importante rival de la industria. El 31 de agosto, la compañía anunció una ronda de financiamiento masiva de $ 1.6 mil millones con una valoración de $ 38 mil millones, solo unos meses después de una ronda de $ 1 mil millones anunciada en febrero de 2021 (con una valuación miserable de $ 28 mil millones).
Hasta hace poco, Snowflake y Databricks estaban en segmentos bastante diferentes del mercado (y de hecho fueron socios cercanos durante un tiempo).
Snowflake, como almacén de datos en la nube, es principalmente una base de datos para almacenar y procesar grandes cantidades de datos estructurados, es decir, datos que pueden caber perfectamente en filas y columnas. Históricamente, se ha utilizado para permitir que las empresas respondan preguntas sobre el desempeño pasado y actual (“¿cuáles fueron nuestras regiones de mayor crecimiento el último trimestre?”), Mediante la incorporación de herramientas de inteligencia empresarial (BI). Al igual que otras bases de datos, aprovecha SQL, un lenguaje de consulta muy popular y accesible, que lo hace utilizable por millones de usuarios potenciales en todo el mundo.
Los ladrillos de datos provienen de un rincón diferente del mundo de los datos. Comenzó en 2013 a comercializar Spark, un marco de código abierto para procesar grandes volúmenes de datos generalmente no estructurados (cualquier tipo de texto, audio, video, etc.). Los usuarios de Spark utilizaron el marco para crear y procesar lo que se conoció como “lagos de datos”, donde volcarían casi cualquier tipo de datos sin preocuparse por la estructura u organización. Un uso principal de los lagos de datos fue entrenar aplicaciones de ML / AI, permitiendo a las empresas responder preguntas sobre el futuro (“¿qué clientes tienen más probabilidades de comprar el próximo trimestre?”, Es decir, análisis predictivo). Para ayudar a los clientes con sus lagos de datos, Databricks creó Delta y, para ayudarlos con ML / AI, creó ML Flow. Para conocer toda la historia de ese viaje, consulte miCharla junto a la chimenea con Ali Ghodsi, director ejecutivo de Databricks .
Más recientemente, sin embargo, las dos empresas se han unido.
Databricks comenzó a agregar capacidades de almacenamiento de datos a sus lagos de datos, lo que permitió a los analistas de datos ejecutar consultas SQL estándar, además de agregar herramientas de inteligencia empresarial como Tableau o Microsoft Power BI. El resultado es lo que Databricks llama la casa del lago: una plataforma destinada a combinar lo mejor de los almacenes de datos y los lagos de datos.
A medida que Databricks hizo que sus lagos de datos se parecieran más a almacenes de datos, Snowflake ha ido haciendo que sus almacenes de datos se parezcan más a lagos de datos. Se ha anunciado soporte para datos no estructurados, tales como audio, vídeo, archivos PDF y los datos de imágenes en noviembre de 2020 y lanzado en vista previa hace tan sólo unos días.
Y donde Databricks ha estado agregando BI a sus capacidades de IA, Snowflake está agregando IA a su compatibilidad con BI. Snowflake ha estado construyendo estrechas alianzas con las principales plataformas de inteligencia artificial empresarial. Snowflake invirtió en Dataiku y lo nombró socio de ciencia de datos del año. Es también invirtió en la plataforma ML DataRobot rival .
En última instancia, tanto Snowflake como Databricks quieren ser el centro de todos los datos: un repositorio para almacenar todos los datos, ya sean estructurados o no estructurados, y ejecutar todos los análisis, ya sean históricos (inteligencia empresarial) o predictivos (ciencia de datos, ML / AI).
Por supuesto, no faltan otros competidores con una visión similar. Los hiperescaladores en la nube, en particular, tienen sus propios almacenes de datos, así como un conjunto completo de herramientas analíticas para BI e IA, y muchas otras capacidades, además de la escala masiva. Por ejemplo, escuche este gran episodio del podcast de ingeniería de datos sobre las capacidades de análisis y datos de GCP .
Tanto Snowflake como Databricks han tenido relaciones muy interesantes con los proveedores de la nube, tanto como amigos como enemigos. Es famoso que Snowflake creció gracias a AWS (a pesar del producto competitivo de AWS, Redshift) durante años antes de expandirse a otras plataformas en la nube. Databricks construyó una sólida asociación con Microsoft Azure y ahora promociona sus capacidades de múltiples nubes para ayudar a los clientes a evitar el bloqueo de los proveedores de la nube. Durante muchos años, y hasta el día de hoy, hasta cierto punto, los detractores enfatizaron que los modelos comerciales de Snowflake y Databricks revenden de manera efectiva la computación subyacente de los proveedores de la nube, que ponen sus márgenes brutos a merced de las decisiones de precios que tomarían los hiperescaladores.
Ver el baile entre los proveedores de la nube y los gigantes de los datos será una historia definitoria de los próximos cinco años.
¿Agrupación, desagregación, consolidación?
Dado el auge de Snowflake y Databricks, algunos observadores de la industria se preguntan si este es el comienzo de una tan esperada ola de consolidación en la industria: consolidación funcional a medida que las grandes empresas agrupan una cantidad cada vez mayor de capacidades en sus plataformas y gradualmente hacen que las nuevas empresas más pequeñas sean irrelevantes. y / o consolidación corporativa , ya que las grandes empresas compran a las más pequeñas o las expulsan del negocio.
Ciertamente, la consolidación funcional está ocurriendo en el espacio de datos e inteligencia artificial, a medida que los líderes de la industria aumentan sus ambiciones. Este es claramente el caso de Snowflake y Databricks, y los hiperescaladores de la nube, como se acaba de comentar.
Pero otros también tienen grandes planes. A medida que crecen, las empresas quieren agrupar cada vez más funcionalidades; nadie quiere ser una empresa de un solo producto.
Por ejemplo, Confluent, una plataforma para la transmisión de datos que se hizo pública en junio de 2021, quiere ir más allá de los casos de uso de datos en tiempo real por los que es conocida y “unificar el procesamiento de datos en movimiento y datos en reposo” (ver nuestro desmontaje rápido S-1: confluente ).
Como otro ejemplo, Dataiku * cubre de forma nativa toda la funcionalidad que ofrecen docenas de startups de infraestructura de IA y datos especializados, desde la preparación de datos hasta el aprendizaje automático, DataOps, MLOps, visualización, explicabilidad de IA, etc., todo incluido en una plataforma, con un centrarse en la democratización y la colaboración (consulte nuestro Fireside Chat con Florian Douetteau, director ejecutivo de Dataiku ).
Podría decirse que el auge de la “pila de datos moderna” es otro ejemplo de consolidación funcional. En esencia, es una alianza de facto entre un grupo de empresas (en su mayoría startups) que, como grupo, cubren funcionalmente todas las diferentes etapas del viaje de datos desde la extracción hasta el almacén de datos y la inteligencia empresarial, el objetivo general es ofrecer al mercado un conjunto coherente de soluciones que se integren entre sí.
Para los usuarios de esas tecnologías, esta tendencia hacia la agrupación y la convergencia es saludable, y muchos la recibirán con los brazos abiertos. A medida que madura, es hora de que la industria de los datos evolucione más allá de sus grandes divisiones tecnológicas: transaccional frente a analítica, por lotes frente a tiempo real, BI frente a IA .
Estas divisiones algo artificiales tienen raíces profundas, tanto en la historia del ecosistema de datos como en las limitaciones tecnológicas. Cada segmento tuvo sus propios desafíos y evolución, lo que resultó en una pila de tecnología diferente y un conjunto diferente de proveedores. Esto ha generado mucha complejidad para los usuarios de esas tecnologías. Los ingenieros han tenido que unir conjuntos de herramientas y soluciones y mantener sistemas complejos que a menudo terminan pareciéndose a las máquinas de Rube Goldberg.
A medida que continúan creciendo, esperamos que los líderes de la industria aceleren sus esfuerzos de agrupación y sigan impulsando mensajes como “análisis de datos unificados”. Esta es una buena noticia para las empresas de Global 2000 en particular, que han sido el principal cliente objetivo de las plataformas de inteligencia artificial y datos empaquetados más grandes. Esas empresas tienen mucho que ganar con la implementación de una infraestructura de datos moderna y ML / AI, y al mismo tiempo un acceso mucho más limitado a los datos principales y al talento de ingeniería de ML necesarios para construir o ensamblar la infraestructura de datos internamente (como suele ocurrir con ese talento). preferir trabajar en empresas de Big Tech o en startups prometedoras, en general).
Sin embargo, por mucho que Snowflake y Databricks quisieran convertirse en el único proveedor de todo lo relacionado con los datos y la inteligencia artificial, creemos que las empresas seguirán trabajando con múltiples proveedores, plataformas y herramientas, en la combinación que mejor se adapte a sus necesidades.
La razón clave: el ritmo de la innovación es demasiado explosivo en el espacio para que las cosas permanezcan estáticas durante demasiado tiempo. Los fundadores lanzan nuevas empresas emergentes; Las grandes empresas tecnológicas crean herramientas internas de datos / inteligencia artificial y luego las abren; y por cada tecnología o producto establecido, parece surgir uno nuevo cada semana. Incluso el espacio de almacenamiento de datos, posiblemente el segmento más establecido del ecosistema de datos en la actualidad, tiene nuevos participantes como Firebolt , que promete un rendimiento muy superior.
Si bien las grandes plataformas integradas tienen empresas de Global 2000 como base de clientes principal, existe un ecosistema completo de empresas de tecnología, tanto startups como Big Tech, que son ávidos consumidores de todas las nuevas herramientas y tecnologías, lo que brinda a las startups detrás de ellas un gran mercado inicial. . Esas empresas tienen acceso a los datos correctos y al talento de ingeniería de ML, y están dispuestas y son capaces de combinar las mejores herramientas nuevas para ofrecer las soluciones más personalizadas.
Mientras tanto, justo cuando los proveedores de big data warehouse y data lake están presionando a sus clientes para que centralicen todas las cosas en la parte superior de sus plataformas, surgen nuevos marcos como la malla de datos, que abogan por un enfoque descentralizado, donde diferentes equipos son responsables de sus propios producto de datos. Si bien hay muchos matices, una implicación es evolucionar lejos de un mundo donde las empresas simplemente mueven todos sus datos a un gran repositorio central. Si se afianza, la malla de datos podría tener un impacto significativo en las arquitecturas y el panorama general de proveedores (más sobre la malla de datos más adelante en esta publicación).
Más allá de la consolidación funcional, tampoco está claro cuánta consolidación corporativa (M&A) ocurrirá en el futuro cercano .
Es probable que veamos algunas adquisiciones muy grandes de miles de millones de dólares, ya que los grandes jugadores están ansiosos por hacer grandes apuestas en este mercado de rápido crecimiento para continuar construyendo sus plataformas empaquetadas. Sin embargo, las altas valoraciones de las empresas de tecnología en el mercado actual probablemente seguirán disuadiendo a muchos compradores potenciales. Por ejemplo, el rumor de la industria favorito de todos ha sido que Microsoft querría adquirir Databricks. Sin embargo, debido a que la empresa podría obtener una valoración de 100.000 millones de dólares o más en los mercados públicos, es posible que ni siquiera Microsoft pueda permitírselo.
También hay un apetito voraz por comprar nuevas empresas más pequeñas en todo el mercado, particularmente a medida que las nuevas empresas en etapas posteriores siguen aumentando y tienen mucho dinero en efectivo a mano. Sin embargo, también existe un interés voraz por parte de los capitalistas de riesgo para continuar financiando esas pequeñas empresas emergentes. Es raro que los datos prometedores y las nuevas empresas de inteligencia artificial en estos días no puedan recaudar la próxima ronda de financiamiento. Como resultado, comparativamente se realizan pocos acuerdos de fusiones y adquisiciones en estos días, ya que muchos fundadores y sus capitalistas de riesgo quieren seguir girando la siguiente tarjeta, en lugar de unir fuerzas con otras empresas, y tienen los recursos financieros para hacerlo.
Profundicemos más en las tendencias de financiación y salida.
Financiaciones, OPI, fusiones y adquisiciones: un mercado loco
Como sabe cualquiera que siga el mercado de las startups, ha sido una locura.
El capital de riesgo se ha desplegado a un ritmo sin precedentes, aumentando un 157% interanual a nivel mundial a $ 156 mil millones en el segundo trimestre de 2021 según CB Insights. Las valoraciones cada vez más altas llevaron a la creación de 136 unicornios recién acuñados solo en la primera mitad de 2021, y la ventana de la OPI se ha abierto de par en par , con las financiaciones públicas (OPI, DL, SPAC) hasta un 687% (496 frente a 63) en el período del 1 de enero al 1 de junio de 2021 frente al mismo período en 2020.
En este contexto general de impulso del mercado, los datos y ML / AI han sido categorías de inversión calientes una vez más el año pasado.
Mercados publicos
No hace mucho tiempo, apenas existían empresas de inteligencia artificial / datos de “juego puro” que cotizaran en los mercados públicos.
Sin embargo, la lista está creciendo rápidamente después de un año sólido para las OPI en el mundo de los datos / IA. Comenzamos un índice de mercado público para ayudar a rastrear el desempeño de esta categoría creciente de empresas públicas; consulte nuestro Índice de empresas públicas de MAD (actualización próximamente).
En el frente de la OPI, fueron particularmente notables UiPath, una empresa de automatización de RPA e IA, y Confluent, una empresa de infraestructura de datos centrada en la transmisión de datos en tiempo real (consulte nuestro desmontaje de Confluent S-1 para nuestro análisis). Otras OPI notables fueron C3.ai, una plataforma de inteligencia artificial (consulte nuestro desmontaje de C3 S-1 ) y Couchbase, una base de datos sin SQL.
Varias empresas verticales de inteligencia artificial también tuvieron OPI notables: SentinelOne, una plataforma autónoma de seguridad de terminales de inteligencia artificial; TuSimple, un desarrollador de camiones autónomos; Zymergen, una empresa de biofabricación; Recursion, una empresa de descubrimiento de fármacos impulsada por la inteligencia artificial; y Darktrace, una empresa “líder mundial en inteligencia artificial para ciberseguridad”.
Mientras tanto, las empresas de datos públicos / IA existentes han seguido obteniendo buenos resultados.
Si bien ambos están fuera de sus máximos históricos, Snowflake es una formidable compañía de capitalización de mercado de $ 95 mil millones y, a pesar de toda la controversia, Palantir es una compañía de capitalización de mercado de $ 55 mil millones, en el momento de escribir este artículo.
Tanto Datadog como MongoDB están en sus máximos históricos. Datadog es ahora una empresa de capitalización de mercado de 45.000 millones de dólares (una lección importante para los inversores). MongoDB es una empresa de $ 33 mil millones, impulsada por el rápido crecimiento de su producto en la nube, Atlas.
En general, como grupo, las empresas de datos y ML / AI han superado ampliamente al mercado en general. Y continúan generando altas primas: de las 10 principales empresas con la mayor capitalización de mercado para el múltiplo de ingresos, 4 de ellas (incluidas las 2 principales) son empresas de datos / IA.
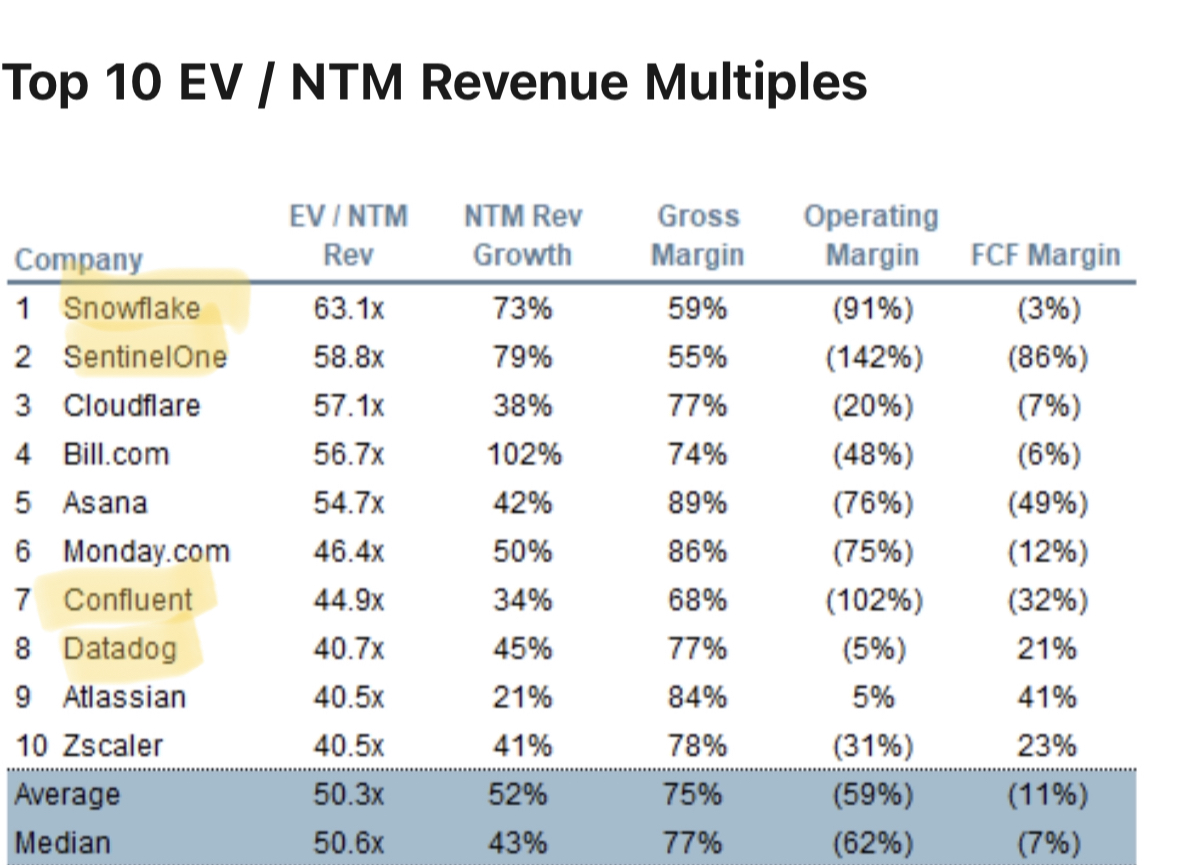
Arriba: Fuente: Jamin Ball, Juicio nublado, 24 de septiembre de 2021
Mercados privados
La espuma del mercado de capital de riesgo es un tema para otra publicación de blog (¿solo una consecuencia de la macroeconomía y las bajas tasas de interés, o un reflejo del hecho de que realmente hemos entrado en la fase de implementación de Internet?). Pero basta con decir que, en el contexto de un mercado de capital de riesgo en auge general, los inversores han mostrado un gran entusiasmo por las nuevas empresas de datos / IA.
Según CB Insights, en la primera mitad de 2021, los inversores habían invertido $ 38 mil millones en nuevas empresas de inteligencia artificial, superando la cantidad total de 2020 de $ 36 mil millones con medio año para el final. Esto fue impulsado por más de 50 rondas de más de $ 100 millones de mega-tamaño, también un nuevo récord. Cuarenta y dos empresas de inteligencia artificial alcanzaron valoraciones de unicornio en la primera mitad del año, en comparación con solo 11 para la totalidad de 2020.
Una característica ineludible del mercado de VC 2020-2021 ha sido el aumento de fondos cruzados, como Tiger Global, Coatue, Altimeter, Dragoneer o D1, y otros megafondos como Softbank o Insight. Si bien esos fondos han estado activos en Internet y el panorama del software, los datos y ML / AI han sido claramente un tema de inversión clave.
Como ejemplo, Tiger Global parece amar a las empresas de datos / IA. Solo en los últimos 12 meses, el fondo de cobertura de Nueva York ha emitido grandes cheques en muchas de las empresas que aparecen en nuestro panorama, incluidas, por ejemplo, Deep Vision, Databricks, Dataiku *, DataRobot, Imply, Prefect, Gong, PathAI, Ada. *, Vast Data, Scale AI, Redis Labs, 6sense, TigerGraph, UiPath, Cockroach Labs *, Hyperscience * y muchos otros.
Este entorno de financiación excepcional ha sido en su mayoría una gran noticia para los fundadores. Muchas empresas de datos / inteligencia artificial se encontraron a sí mismas objeto de rondas preventivas y guerras de ofertas, lo que les dio a los fundadores todo el poder para controlar sus procesos de recaudación de fondos. A medida que las empresas de capital riesgo compitieron para invertir, los tamaños de las rondas y las valoraciones aumentaron drásticamente. Los tamaños redondos de la Serie A solían estar en el rango de $ 8- $ 12 millones hace solo unos años. Ahora se encuentran habitualmente en el rango de $ 15 a $ 20 millones. Las valoraciones de la Serie A que solían estar en el rango de $ 25- $ 45 millones (antes del dinero) ahora a menudo alcanzan los $ 80- $ 120 millones, valoraciones que se habrían considerado una gran valoración de la Serie B hace solo unos años.
Por otro lado, la avalancha de capital ha llevado a un mercado laboral cada vez más ajustado, con una feroz competencia por los datos, el aprendizaje automático y el talento de inteligencia artificial entre muchas empresas emergentes bien financiadas y la correspondiente inflación de compensación.
Otra desventaja: a medida que los capitalistas de riesgo invirtieron agresivamente en sectores emergentes hacia arriba y hacia abajo en la pila de datos, a menudo apostando por el crecimiento futuro sobre la tracción comercial existente, algunas categorías pasaron de nacientes a saturadas muy rápidamente: ETL inverso, calidad de datos, catálogos de datos, anotación de datos y MLOps.
Independientemente, desde nuestro último panorama, una cantidad sin precedentes de empresas de datos / IA se convirtieron en unicornios, y las que ya eran unicornios se volvieron aún más valoradas, con un par de decacorns (Databricks, Celonis).
Algunos financiamientos tipo unicornio dignos de mención (en orden cronológico inverso aproximado): Fivetran, una empresa ETL, recaudó 565 millones de dólares con una valoración de 5.600 millones de dólares; Matillion, una empresa de integración de datos, recaudó $ 150 millones con una valoración de $ 1.5 mil millones; Neo4j, un proveedor de bases de datos de gráficos, recaudó $ 325 millones con una valoración de más de $ 2 mil millones; Databricks, un proveedor de data lakehouses, recaudó $ 1.6 mil millones con una valoración de $ 38 mil millones; Dataiku *, una plataforma de inteligencia artificial empresarial colaborativa, recaudó 400 millones de dólares con una valoración de 4.600 millones de dólares; DBT Labs (fka Fishtown Analytics), un proveedor de herramientas de ingeniería de análisis de código abierto, recaudó una serie C de $ 150 millones; DataRobot, una plataforma de inteligencia artificial empresarial, recaudó $ 300 millones con una valoración de $ 6 mil millones; Celonis, una empresa de minería de procesos, recaudó una serie D de mil millones de dólares con una valoración de 11 mil millones de dólares; Anduril, una empresa de tecnología de defensa con inteligencia artificial, recaudó una ronda de 450 millones de dólares con una valoración de 4.600 millones de dólares; Gong, una plataforma de inteligencia artificial para el análisis y el coaching de equipos de ventas, recaudó 250 millones de dólares con una valoración de 7.250 millones de dólares; Alation, una empresa de gestión y descubrimiento de datos, recaudó una serie D de 110 millones de dólares con una valoración de 1.200 millones de dólares; Ada *, una empresa de chatbot de inteligencia artificial, recaudó una serie C de 130 millones de dólares con una valoración de 1.200 millones de dólares; Signifyd, una empresa de software de protección contra el fraude basada en inteligencia artificial, recaudó 205 millones de dólares con una valoración de 1.340 millones de dólares; Redis Labs, una plataforma de datos en tiempo real, recaudó una serie G de $ 310 millones con una valoración de $ 2 mil millones; Sift, una empresa de prevención de fraude con inteligencia artificial, recaudó 50 millones de dólares a una valoración de más de mil millones de dólares; Tractable, una compañía de seguros pionera en inteligencia artificial, recaudó $ 60 millones con una valoración de $ 1 mil millones; SambaNova Systems, una plataforma informática y de semiconductores de inteligencia artificial especializada, que recaudó 676 millones de dólares con una valoración de 5.000 millones de dólares; Scale AI, una empresa de anotación de datos, recaudó $ 325 millones con una valoración de $ 7 mil millones; Vectra, una empresa de inteligencia artificial de ciberseguridad, recaudó 130 millones de dólares con una valoración de 1.200 millones de dólares; Shift Technology, una empresa de software pionera en inteligencia artificial creada para aseguradoras, recaudó 220 millones de dólares; Dataminr, una plataforma de detección de riesgos de IA en tiempo real, recaudó $ 475 millones; Feedzai, una empresa de detección de fraudes, recaudó una ronda de $ 200 millones con una valoración de más de $ 1 mil millones; Cockroach Labs *, un proveedor de bases de datos SQL nativo de la nube, recaudó $ 160 millones con una valoración de $ 2 mil millones; Starburst Data, un motor de consulta de datos basado en SQL, recaudó una ronda de $ 100 millones con una valoración de $ 1.2 mil millones; K Health, un proveedor de atención médica virtual móvil primero en inteligencia artificial, recaudó $ 132 millones con una valoración de $ 1.5 mil millones; Graphcore, un fabricante de chips de IA, recaudó 222 millones de dólares; y Forter, una empresa de software de detección de fraudes, recaudó una ronda de 125 millones de dólares con una valoración de 1.300 millones de dólares.
Adquisiciones
Como se mencionó anteriormente, las adquisiciones en el espacio MAD han sido sólidas, pero no se han disparado tanto como uno habría adivinado, dado el mercado caliente. La cantidad sin precedentes de efectivo que flota en el ecosistema recorta en ambos sentidos: más empresas tienen balances sólidos para adquirir potencialmente otras, pero muchos objetivos potenciales también tienen acceso a efectivo, ya sea en mercados privados / VC o en mercados públicos, y es menos probable que lo hagan. quiere ser adquirido.
Por supuesto, ha habido varias adquisiciones muy importantes: Nuance, una empresa pública de reconocimiento de voz y texto (con un enfoque particular en la atención médica), está en proceso de ser adquirida por Microsoft por casi $ 20 mil millones (lo que la convierte en la segunda adquisición más grande de Microsoft). siempre, después de LinkedIn); Blue Yonder, una empresa de software de cadena de suministro pionera en inteligencia artificial para clientes minoristas, de fabricación y de logística, fue adquirida por Panasonic por hasta 8.500 millones de dólares; Twilio adquirió Segment, una plataforma de datos de clientes, por 3.200 millones de dólares; Kustomer, un CRM que permite a las empresas gestionar de forma eficaz todas las interacciones con los clientes en todos los canales, fue adquirido por Facebook por mil millones de dólares; y Turbonomic, una empresa de “Gestión de recursos de aplicaciones impulsada por IA”, fue adquirida por IBM por entre $ 1,5 mil millones y $ 2 mil millones.
También hubo un par de adquisiciones privadas de empresas públicas por parte de firmas de capital privado: Cloudera, una plataforma de datos anteriormente de alto vuelo, fue adquirida por Clayton Dubilier & Rice y KKR, quizás el final oficial de la era Hadoop; y Thoma Bravo hizo privado a Talend, un proveedor de integración de datos.
Algunas otras adquisiciones notables de empresas que aparecieron en versiones anteriores de este panorama MAD: ZoomInfo adquirió Chorus.ai y Everstring; DataRobot adquirió Algoritmia; Cloudera adquirió Cazena; Relatividad adquirida Text IQ *; Datadog adquirió Sqreen y Timber *; SmartEye adquirió Affectiva; Facebook adquirió Kustomer; ServiceNow adquirió Element AI; Vista Equity Partners adquirió Gainsight; AVEVA adquirió OSIsoft; y American Express adquirió Kabbage.
Novedades para el panorama MAD 2021
Dado el ritmo explosivo de innovación, creación de empresas y financiación en 2020-21, especialmente en infraestructura de datos y MLOps, hemos tenido que cambiar bastante las cosas en el panorama de este año.
Un cambio estructural significativo: como ya no podíamos encajarlo todo en una categoría, dividimos “Análisis e inteligencia artificial” en dos categorías separadas, “Análisis” y “Aprendizaje automático e inteligencia artificial”.
Agregamos varias categorías nuevas:
- En “Infraestructura”, agregamos:
- ” ETL inverso “: productos que canalizan los datos desde el almacén de datos a las aplicaciones SaaS
- ” Observabilidad de datos “: un componente emergente de DataOps que se centra en comprender y solucionar la raíz de los problemas de calidad de los datos, con el linaje de los datos como base fundamental.
- ” Privacidad y seguridad “: la privacidad de los datos es cada vez más una prioridad y han surgido varias empresas emergentes en la categoría
- En “Analytics”, agregamos:
- “ Data Catalogs & Discovery ”: una de las categorías más ocupadas de los últimos 12 meses; Son productos que permiten a los usuarios (tanto técnicos como no técnicos) encontrar y gestionar los conjuntos de datos que necesitan.
- ” Análisis aumentado “: las herramientas de BI aprovechan los avances de NLG / NLP para generar conocimientos de forma automática, en particular, democratizar los datos para audiencias menos técnicas.
- ” Metrics Stores “: un nuevo participante en la pila de datos que proporciona un lugar centralizado y estandarizado para ofrecer métricas comerciales clave.
- ” Motores de consulta “
- En “Machine Learning and AI”, dividimos varias categorías de MLOps en subcategorías más granulares:
- ” Construcción de modelos “
- ” Tiendas de características “
- ” Implementación y producción “
- En “Código abierto”, agregamos:
- ” Formato “
- ” Orquestación “
- ” Observabilidad y calidad de los datos “
Otra evolución significativa: en el pasado, tendíamos a presentar abrumadoramente en el panorama a las empresas más establecidas: empresas emergentes en etapa de crecimiento (Serie C o posterior), así como empresas públicas. Sin embargo, dado el surgimiento de la nueva generación de empresas de datos / IA mencionada anteriormente, este año hemos presentado muchas más startups tempranas (serie A, a veces semilla) que nunca.
Sin más preámbulos, aquí está el panorama:

Arriba: Gráfico de mattturck.com que muestra las tendencias clave de 2021 en infraestructura de datos.
- VER LA TABLA EN TAMAÑO COMPLETO y ALTA RESOLUCIÓN: HAGA CLIC AQUÍ
- LISTA COMPLETA EN FORMATO DE HOJA DE CÁLCULO: A pesar de lo ajetreado que está el panorama, no podemos encajar en todas las empresas interesantes del gráfico en sí. Como resultado, tenemos una hoja de cálculo completa que no solo enumera todas las empresas en el panorama, sino también cientos más – HAGA CLIC AQUÍ
Tendencias clave en la infraestructura de datos
En el panorama del año pasado , identificamos algunas de las tendencias clave de la infraestructura de datos de 2020:
Como recordatorio, estas son algunas de las tendencias que escribimos sobre el ÚLTIMO AÑO (2020):
- La pila de datos moderna se generaliza
- ETL frente a ELT
- ¿Automatización de la ingeniería de datos?
- Ascenso del analista de datos
- ¿Lagos de datos y los almacenes de datos se fusionan?
- La complejidad permanece
Por supuesto, el informe de 2020 tiene menos de un año, y esas son tendencias de varios años que aún se están desarrollando y continuarán haciéndolo.
Ahora, aquí está nuestro resumen de algunas tendencias clave para ESTE AÑO (2021):
- La malla de datos
- Un año ajetreado para DataOps
- Es hora de tiempo real
- Tiendas de métricas
- ETL inverso
- Compartir datos
La malla de datos
El nuevo tema favorito de todos de 2021 es la “malla de datos”, y ha sido divertido verlo debatido en Twitter entre el grupo (ciertamente bastante pequeño) de personas que se obsesionan con esos temas.
El concepto fue presentado por primera vez por Zhamak Dehghani en 2019 (consulte su artículo original, ” Cómo pasar de un lago de datos monolítico a una malla de datos distribuidos “), y ha cobrado mucho impulso a lo largo de 2020 y 2021.
El concepto de malla de datos es en gran parte una idea organizativa. Un enfoque estándar para construir equipos e infraestructura de datos hasta ahora ha sido la centralización: una gran plataforma, administrada por un equipo de datos, que atiende las necesidades de los usuarios comerciales. Esto tiene ventajas, pero también puede crear una serie de problemas (cuellos de botella, etc.). El concepto general de la malla de datos es la descentralización: crear equipos de datos independientes que sean responsables de su propio dominio y proporcionen datos “como un producto” a otros dentro de la organización. Conceptualmente, esto no es completamente diferente del concepto de microservicios que se ha vuelto familiar en la ingeniería de software, pero que se aplica al dominio de los datos.
La malla de datos tiene una serie de importantes implicaciones prácticas que se están debatiendo activamente en los círculos de datos.
Si se afianzara, sería un gran viento de cola para las nuevas empresas que brindan el tipo de herramientas que son críticas para la misión en una pila de datos descentralizada.
Starburst, un motor de consultas SQL para acceder y analizar datos a través de repositorios, se ha rebautizado a sí mismo como “el motor de análisis para la malla de datos”. Incluso patrocina el nuevo libro de Dehghani sobre el tema.
Las tecnologías como los motores de orquestación (Airflow, Prefect, Dagster) que ayudan a administrar tuberías complejas se volverían aún más críticas para la misión. Vea mi charla de Fireside con Nick Schrock (Fundador y CEO, Elementl) , la compañía detrás del motor de orquestación Dagster.
El seguimiento de datos a través de repositorios y canalizaciones se volvería aún más esencial para fines de resolución de problemas, así como para el cumplimiento y la gobernanza, lo que refuerza la necesidad de un linaje de datos. La industria se está preparando para este mundo, por ejemplo, con OpenLineage , una nueva iniciativa entre industrias para la recopilación estándar de linajes de datos. Vea mi charla junto a la chimenea con Julien Le Dem, director de tecnología de Datakin *, la empresa que ayudó a iniciar la iniciativa OpenLineage.
*** Para cualquier persona interesada, presentaremos a Zhamak Dehghani en Data Driven NYC el 14 de octubre de 2021. ¡Será una sesión de Zoom, abierta a todos! Ingrese su dirección de correo electrónico aquí para recibir una notificación sobre el evento. ***
Un año ajetreado para DataOps
Si bien el concepto de DataOps ha estado flotando durante años (y lo mencionamos en versiones anteriores de este panorama), la actividad realmente se ha recuperado recientemente.
Como suele ser el caso de las categorías más nuevas, la definición de DataOps es algo confusa. Algunos lo ven como la aplicación de DevOps (del software mundial de ingeniería) al mundo de los datos; otros lo ven de manera más amplia como cualquier cosa que implique la creación y mantenimiento de canalizaciones de datos y la garantía de que todos los productores y consumidores de datos puedan hacer lo que necesitan hacer, ya sea encontrar el conjunto de datos correcto (a través de un catálogo de datos) o implementar un modelo en producción. Independientemente, al igual que DevOps, es una combinación de metodología, procesos, personas, plataformas y herramientas.
El contexto general es que las herramientas y prácticas de ingeniería de datos todavía están muy por detrás del nivel de sofisticación y automatización de sus primos de ingeniería de software.
El surgimiento de DataOps es uno de los ejemplos de lo que mencionamos anteriormente en la publicación: dado que las necesidades básicas en torno al almacenamiento y procesamiento de datos ahora se abordan adecuadamente, y los datos / IA se están volviendo cada vez más críticos para la misión en la empresa, la industria lo es naturalmente evolucionando hacia los siguientes niveles de la jerarquía de necesidades de datos y creando mejores herramientas y prácticas para garantizar que la infraestructura de datos pueda funcionar y mantenerse de manera confiable y a escala.
Todo un ecosistema de startups de DataOps en etapa inicial que surgieron recientemente, cubriendo diferentes partes de la categoría, pero con más o menos la misma ambición de convertirse en el “Datadog del mundo de los datos” (mientras que Datadog a veces se usa para fines de DataOps y puede entrar en el espacio en un momento u otro, históricamente se ha centrado en la ingeniería y las operaciones de software).
Las empresas emergentes están compitiendo para definir su subcategoría, por lo que hay muchos términos flotando, pero estos son algunos de los conceptos clave.
La observabilidad de datos es el concepto general de usar monitoreo, alertas y clasificación automatizados para eliminar el “tiempo de inactividad de los datos”, un término acuñado por Monte Carlo Data, un proveedor en el espacio (junto con otros como BigEye y Databand).
La observabilidad tiene dos pilares básicos. Uno es el linaje de datos, que es la capacidad de seguir el camino de los datos a través de canalizaciones y comprender dónde surgen los problemas y de dónde provienen los datos (para fines de cumplimiento). El linaje de datos tiene su propio conjunto de nuevas empresas especializadas como Datakin * y Manta.
El otro pilar es la calidad de los datos, que ha visto una avalancha de nuevos participantes. Detectar problemas de calidad en los datos es esencial y mucho más complicado que en el mundo de la ingeniería de software, ya que cada conjunto de datos es un poco diferente. Diferentes startups tienen diferentes enfoques. Uno es declarativo, lo que significa que las personas pueden establecer reglas explícitamente sobre qué es un conjunto de datos de calidad y qué no lo es. Este es el enfoque de Superconductive, la compañía detrás del popular proyecto de código abierto Great Expectations (consulte nuestro Fireside Chat con Abe Gong, CEO de Superconductive ). Otro enfoque se basa más en el aprendizaje automático para automatizar la detección de problemas de calidad (sin dejar de usar algunas reglas): Anomalo es una startup con este enfoque.
Un concepto emergente relacionado es la ingeniería de confiabilidad de datos (DRE), que se hace eco de la disciplina hermana de la ingeniería de confiabilidad de sitios (SRE) en el mundo de la infraestructura de software. Los DRE son ingenieros que resuelven problemas operativos / de escala / confiabilidad para la infraestructura de datos. Espere que aparezcan más herramientas (alertas, comunicación, intercambio de conocimientos, etc.) en el mercado para satisfacer sus necesidades.
Por último, el acceso y la gobernanza de los datos es otra parte de DataOps (definida en términos generales) que ha experimentado una explosión de actividad. Las empresas emergentes en etapa de crecimiento como Collibra y Alation han estado proporcionando capacidades de catálogo durante algunos años, básicamente un inventario de datos disponibles que ayuda a los analistas de datos a encontrar los datos que necesitan. Sin embargo, varios nuevos participantes se han unido al mercado más recientemente, incluidos Atlan y Stemma, la empresa comercial detrás del catálogo de datos de código abierto Amundsen (que comenzó en Lyft).
Es hora de tiempo real
Los datos en “tiempo real” o “en tiempo real” son datos que se procesan y consumen inmediatamente después de su generación. Esto se opone al “lote”, que ha sido el paradigma dominante en la infraestructura de datos hasta la fecha.
Se nos ocurrió una analogía para explicar la diferencia: Batch es como bloquear una hora para revisar su bandeja de entrada y responder a su correo electrónico; La transmisión es como enviar mensajes de texto con alguien.
El procesamiento de datos en tiempo real ha sido un tema candente desde los primeros días de la era de Big Data, hace 10-15 años; en particular, la velocidad de procesamiento fue una ventaja clave que precipitó el éxito de Spark (un marco de micro lotes) sobre Hadoop MapReduce. .
Sin embargo, durante años, la transmisión de datos en tiempo real fue siempre el segmento de mercado que estaba “a punto de explotar” de una manera muy importante, pero nunca lo hizo del todo. Algunos observadores de la industria argumentaron que la cantidad de aplicaciones para datos en tiempo real es, quizás de manera contraintuitiva, bastante limitada, y gira en torno a un número finito de casos de uso como detección de fraude en línea, publicidad en línea, recomendaciones de contenido al estilo de Netflix o ciberseguridad.
El rotundo éxito de la OPI de Confluent ha demostrado que los detractores estaban equivocados. Confluent es ahora una compañía de capitalización de mercado de $ 17 mil millones al momento de escribir este artículo, habiéndose casi duplicado desde su OPI del 24 de junio de 2021. Confluent es la compañía detrás de Kafka, un proyecto de transmisión de datos de código abierto desarrollado originalmente en LinkedIn. A lo largo de los años, la compañía evolucionó hasta convertirse en una plataforma de transmisión de datos a gran escala que permite a los clientes acceder y administrar datos como transmisiones continuas en tiempo real (nuevamente, nuestro desmontaje S-1 está aquí ).
Más allá de Confluent, todo el ecosistema de datos en tiempo real se ha acelerado.
El análisis de datos en tiempo real, en particular, ha experimentado mucha actividad. Hace solo unos días, ClickHouse, una base de datos de análisis en tiempo real que originalmente era un proyecto de código abierto lanzado por el motor de búsqueda ruso Yandex, anunció que se ha convertido en una empresa comercial con sede en EE. UU. Financiada con 50 millones de dólares en capital de riesgo. A principios de este año, Imply, otra plataforma de análisis en tiempo real basada en el proyecto de base de datos de código abierto Druid, anunció una ronda de financiación de 70 millones de dólares. Materialise es otra empresa muy interesante en el espacio; vea nuestro Fireside Chat con Arjun Narayan, CEO de Materialise .
Antes del análisis de datos, los actores emergentes ayudan a simplificar las canalizaciones de datos en tiempo real. Meroxa se enfoca en conectar bases de datos relacionales a almacenes de datos en tiempo real; vea nuestro Fireside Chat con DeVaris Brown, CEO de Meroxa . Estuary * se centra en unificar los paradigmas en tiempo real y por lotes en un esfuerzo por abstraer la complejidad.
Tiendas de métricas
El uso de datos y datos aumentó tanto en frecuencia como en complejidad en las empresas durante los últimos años. Con ese aumento en la complejidad viene un aumento acompañado de dolores de cabeza causados por inconsistencias en los datos. Para cualquier métrica específica, cualquier pequeña derivación en la métrica, ya sea causada por dimensión, definición u otra cosa, puede causar resultados desalineados. Los equipos que se percibe que están trabajando en base a las mismas métricas podrían estar trabajando con diferentes cortes de datos por completo o las definiciones de métricas pueden cambiar ligeramente entre los momentos en que se realiza el análisis y llevar a resultados diferentes, sembrando desconfianza cuando surgen inconsistencias. Los datos solo son útiles si los equipos pueden confiar en que los datos son precisos cada vez que los utilizan.
Esto ha llevado al surgimiento de la tienda de métricas que Benn Stancil, el director de análisis de Mode, denominó la pieza que faltaba en la pila de datos moderna . Las soluciones locales que buscan centralizar el lugar donde se definen las métricas se anunciaron en empresas de tecnología como AirBnB, donde Minerva tiene la visión de “definir una vez, usar en cualquier lugar” y en Pinterest.. Estos almacenes de métricas internas sirven para estandarizar las definiciones de métricas comerciales clave y todas sus dimensiones, y proporcionan a las partes interesadas conjuntos de datos precisos y listos para el análisis basados en esas definiciones. Al centralizar la definición de métricas, estas tiendas ayudan a los equipos a generar confianza en los datos que están utilizando y democratizar el acceso multifuncional a las métricas, impulsando la alineación de datos en toda la empresa.
El almacén de métricas se encuentra en la parte superior del almacén de datos e informa los datos enviados a todas las aplicaciones posteriores donde se consumen los datos, incluidas las plataformas de inteligencia empresarial, las herramientas de análisis y ciencia de datos y las aplicaciones operativas. Los equipos definen métricas comerciales clave en el almacén de métricas, lo que garantiza que cualquiera que utilice una métrica específica la obtendrá utilizando definiciones coherentes. Las tiendas de métricas como Minerva también aseguran que los datos sean consistentes históricamente, llenándose automáticamente si se cambia la lógica empresarial. Finalmente, el almacén de métricas entrega las métricas al consumidor de datos en formatos estandarizados y validados. El almacén de métricas permite que los consumidores de datos de diferentes equipos ya no tengan que crear y mantener sus propias versiones de la misma métrica y puedan confiar en una única fuente de verdad centralizada.
Algunas startups interesantes que crean tiendas de métricas incluyen Transform , Trace * y Supergrain .
ETL inverso
Sin duda, ha sido un año ajetreado en el mundo de ETL / ELT, los productos que tienen como objetivo extraer datos de una variedad de fuentes (ya sean bases de datos o productos SaaS) y cargarlos en almacenes de datos en la nube. Como se mencionó, Fivetran se convirtió en una empresa de $ 5.6 mil millones; Mientras tanto, los nuevos participantes Airbyte (una versión de código abierto) recaudaron una serie A de $ 26 millones y Meltano se separó de GitLab.
Sin embargo, un desarrollo clave en la pila de datos moderna durante el último año ha sido la aparición de ETL inversocomo categoría. Con la pila de datos moderna, los almacenes de datos se han convertido en la única fuente de verdad para todos los datos comerciales que históricamente se han distribuido en varios sistemas comerciales de la capa de aplicación. Las herramientas ETL inversas se encuentran en el lado opuesto del almacén de las herramientas ETL / ELT típicas y permiten a los equipos mover datos desde su almacén de datos a aplicaciones comerciales como CRM, sistemas de automatización de marketing o plataformas de soporte al cliente para hacer uso de los datos consolidados y derivados. datos en sus procesos de negocio funcionales. Los ETL inversos se han convertido en una parte integral para cerrar el ciclo en la pila de datos moderna para traer datos unificados, pero vienen con desafíos debido a que los datos se devuelven a los sistemas en vivo.
Con los ETL inversos, los equipos funcionales como el de ventas pueden aprovechar los datos actualizados enriquecidos de otras aplicaciones comerciales, como el compromiso con el producto, de herramientas como Pendo * para comprender cómo un cliente potencial ya está participando o de la programación de marketing de Marketo para tejer una estrategia más coherente. narrativa de ventas. Los ETL inversos ayudan a romper los silos de datos y a impulsar la alineación entre las funciones al llevar datos centralizados desde el almacén de datos a los sistemas en los que estos equipos funcionales ya viven en el día a día.
Varias empresas en el espacio ETL inverso han recibido financiación el año pasado, incluidas Census, Rudderstack, Grouparoo, Hightouch, Headsup y Polytomic.
Compartir datos
Otro tema que se ha acelerado este año ha sido el aumento del intercambio de datos y la colaboración de datos no solo dentro de las empresas, sino también entre las organizaciones.
Las empresas pueden querer compartir datos con su ecosistema de proveedores, socios y clientes por una amplia gama de razones, incluida la visibilidad de la cadena de suministro, la capacitación de modelos de aprendizaje automático o iniciativas compartidas de comercialización.
El intercambio de datos entre organizaciones ha sido un tema clave para los proveedores de “nube de datos” en particular:
- En mayo de 2021, Google lanzó Analytics Hub , una plataforma para combinar conjuntos de datos y compartir datos e información, incluidos paneles y modelos de aprendizaje automático, tanto dentro como fuera de una organización. También lanzó Datashare , un producto dirigido más específicamente a servicios financieros y basado en Analytics Hub.
- El mismo día (!) De mayo de 2021, Databricks anunció Delta Sharing , un protocolo de código abierto para el intercambio seguro de datos entre organizaciones.
- En junio de 2021, Snowflake anunció la disponibilidad general de su mercado de datos, así como capacidades adicionales para el intercambio seguro de datos.
También hay una serie de nuevas empresas interesantes en el espacio:
- Habr, un proveedor de intercambios de datos empresariales
- Crossbeam *, una plataforma de ecosistema de socios
Permitir la colaboración entre organizaciones es particularmente estratégico para los proveedores de nube de datos porque ofrece la posibilidad de construir un foso adicional para sus negocios. A medida que la competencia se intensifica y los proveedores intentan superarse entre sí en características y capacidades, una plataforma de intercambio de datos podría ayudar a crear un efecto de red. Cuantas más empresas se unan, digamos, a Snowflake Data Cloud y compartan sus datos con otros, más valioso será para cada nueva empresa que se una a la red (y más difícil será salir de la red).
Tendencias clave en ML / AI
En el panorama del año pasado , identificamos algunas de las tendencias clave de la infraestructura de datos de 2020.
Como recordatorio, estas son algunas de las tendencias que escribimos sobre el ÚLTIMO AÑO (2020)
- Tiempo de auge para las plataformas de ciencia de datos y aprendizaje automático (DSML)
- El aprendizaje automático se implementa e integra
- El año de la PNL
Ahora, aquí está nuestro resumen de algunas tendencias clave para ESTE AÑO (2021):
- Tiendas de características
- El auge de ModelOps
- Generación de contenido de IA
- La aparición continua de una pila de inteligencia artificial china separada
La investigación en inteligencia artificial sigue mejorando a un ritmo rápido. Algunos proyectos notables lanzados o publicados en el último año incluyen Alphafold de DeepMind, que predice en qué formas se pliegan las proteínas, junto con múltiples avances de OpenAI, incluidos GPT-3, DALL-E y CLIP.
Además, la financiación inicial se ha acelerado drásticamente en toda la pila de aprendizaje automático, dando lugar a una gran cantidad de soluciones puntuales. Con el panorama en crecimiento, es probable que surjan problemas de compatibilidad entre las soluciones a medida que las pilas de aprendizaje automático se vuelven cada vez más complicadas. Las empresas deberán tomar una decisión entre comprar una solución integral completa como DataRobot o Dataiku * o intentar encadenar las mejores soluciones puntuales de su clase. La consolidación a través de soluciones de puntos adyacentes también es inevitable a medida que el mercado madura y las empresas de crecimiento más rápido alcanzan una escala significativa.
Tiendas de características
Las tiendas de características se han vuelto cada vez más comunes en la pila operativa de aprendizaje automático desde que Uber introdujo la idea por primera vez en 2017 , y varias empresas realizaron rondas el año pasado para crear tiendas de características administradas, incluidas Tecton , Rasgo , Logical Clocks y Kaskada .
Una característica (a veces denominada variable o atributo) en el aprendizaje automático es una propiedad o característica de entrada individual medible, que podría representarse como una columna en un fragmento de datos. Los modelos de aprendizaje automático pueden usarse desde una sola función hasta más de millones.
Históricamente, la ingeniería de características se había realizado de una manera más ad-hoc, con modelos y tuberías cada vez más complicados a lo largo del tiempo. Los ingenieros y científicos de datos a menudo dedicaban mucho tiempo a volver a extraer características de los datos sin procesar. Las brechas entre los entornos de producción y experimentación también podrían causar inconsistencias inesperadas en el rendimiento y el comportamiento del modelo. Las organizaciones también están más preocupadas por la gobernanza, la reproducibilidad y la explicabilidad de sus modelos de aprendizaje automático, y las características en silos lo dificultan en la práctica.
Las tiendas de características promueven la colaboración y ayudan a romper los silos. Reducen la complejidad de los gastos generales y estandarizan y reutilizan las funciones al proporcionar una única fuente de información tanto en la capacitación (fuera de línea) como en la producción (en línea). Actúa como un lugar centralizado para almacenar grandes volúmenes de características seleccionadas dentro de una organización, ejecuta las canalizaciones de datos que transforman los datos sin procesar en valores de características y proporciona acceso de lectura de baja latencia directamente a través de API. Esto permite un desarrollo más rápido y ayuda a los equipos a evitar la duplicación de trabajo y a mantener conjuntos de funciones consistentes entre los ingenieros y entre los modelos de capacitación y servicio. Los almacenes de características también producen y muestran metadatos como el linaje de datos para características, monitoreo de estado, deriva tanto para características como para datos en línea, y más.
El auge de ModelOps
En este punto, la mayoría de las empresas reconocen que llevar los modelos de la experimentación a la producción es un desafío, y los modelos en uso requieren un monitoreo constante y una nueva capacitación a medida que los datos cambian. Según IDC, el 28% de todos los proyectos de ML / AI han fallado , y Gartner señala que el 87% de los proyectos de ciencia de datos nunca llegan a la producción. Las operaciones de aprendizaje automático (MLOps), sobre las que escribimos en 2019 , surgieron en los próximos años cuando las empresas buscaron cerrar esas brechas aplicando las mejores prácticas de DevOps. MLOps busca agilizar el rápido desarrollo continuo y la implementación de modelos a escala y, según Gartner , ha alcanzado un pico en el ciclo de la publicidad.
El nuevo concepto de moda en las operaciones de IA está en ModelOps, un superconjunto de MLOps que tiene como objetivo poner en funcionamiento todos los modelos de IA, incluido ML, a un ritmo más rápido en todas las fases del ciclo de vida, desde el entrenamiento hasta la producción. ModelOps cubre tanto herramientas como procesos, lo que requiere un compromiso cultural interdisciplinario uniendo procesos, estandarizando la orquestación de modelos de un extremo a otro, creando un repositorio centralizado para todos los modelos junto con capacidades de gobernanza integrales (abordar el linaje, monitoreo, etc.) e implementar mejor gobernanza, seguimiento y pistas de auditoría para todos los modelos en uso.
En la práctica, ModelOps bien implementado ayuda a aumentar la explicabilidad y el cumplimiento al tiempo que reduce el riesgo para todos los modelos al proporcionar un sistema unificado para implementar, monitorear y gobernar todos los modelos. Los equipos pueden hacer mejores comparaciones entre modelos con procesos estandarizados durante el entrenamiento y la implementación, lanzar modelos con ciclos más rápidos, recibir alertas automáticamente cuando los puntos de referencia de rendimiento del modelo caen por debajo de los umbrales aceptables y comprender el historial y el linaje de los modelos en uso en todo el mundo. organización.
Generación de contenido de IA
La IA ha madurado mucho en los últimos años y ahora se está aprovechando para crear contenido en todo tipo de medios, incluidos texto, imágenes, código y videos. En junio pasado, OpenAI lanzó su primer producto beta comercial: una API centrada en el desarrollador que contenía GPT-3, un poderoso modelo de lenguaje de uso general con 175 mil millones de parámetros. A principios de este año, decenas de miles de desarrolladores habían creado más de 300 aplicaciones en la plataforma, generando un promedio de 4.500 millones de palabras al día.
OpenAI ya firmó varios acuerdos comerciales tempranos, sobre todo con Microsoft, que ha aprovechado GPT-3 dentro de Power Apps para devolver fórmulas basadas en búsquedas semánticas, lo que permite a los “desarrolladores ciudadanos” generar código con capacidad de codificación limitada. Además, GitHub aprovechó OpenAI Codex, un descendiente de GPT-3 que contiene lenguaje natural y miles de millones de líneas de código fuente de repositorios de código público, para lanzar el controvertido Copiloto de GitHub , que tiene como objetivo acelerar la codificación al sugerir funciones completas para autocompletar el código dentro de el editor de código.
Dado que OpenAI se centra principalmente en modelos centrados en el inglés, un número creciente de empresas está trabajando en modelos que no están en inglés. En Europa, la startup alemana Aleph Alpha recaudó $ 27 millones a principios de este año para construir una “infraestructura informática soberana basada en la UE” y ha creado un modelo de lenguaje multilingüe que puede devolver resultados de texto coherentes en alemán, francés, español e italiano, además. a Ingles. Otras empresas que trabajan en modelos específicos de idiomas incluyen AI21 Labs que construye Jurassic-1 en inglés y hebreo, PanGu-α de Huawei y Wudao de la Academia de Inteligencia Artificial de Beijing en chino, e HyperCLOVA de Naver en coreano.
Por el lado de la imagen, OpenAI presentó su modelo de 12 mil millones de parámetros llamado DALL-E en enero pasado, que fue entrenado para crear imágenes plausibles a partir de descripciones de texto. DALL-E ofrece cierto nivel de control sobre múltiples objetos, sus atributos, sus relaciones espaciales e incluso la perspectiva y el contexto.
Además, los medios sintéticos han madurado significativamente desde el irónico Buzzfeed 2018 y Jordan Peele deepfake Obama . Las empresas de consumo han comenzado a aprovechar los medios generados sintéticamente para todo, desde campañas de marketing hasta entretenimiento. A principios de este año, Synthesia * se asoció con Lay y Lionel Messi para crear Messi Messages, una plataforma que permitía a los usuarios generar videoclips de Messi personalizados con los nombres de sus amigos. Algunos otros ejemplos notables en el último año incluyen el uso de inteligencia artificial para reducir la edad de Mark Hamill tanto en apariencia como en voz en The Mandalorian, hacer que Anthony Bourdain narre un diálogo que nunca dijo en Roadrunner , crear un comercial de State Farm que promocione The Last Dance,y crear una voz sintética para Val Kilmer, quien perdió la voz durante el tratamiento para el cáncer de garganta.
Con este avance tecnológico viene un dilema ético y moral. Los medios sintéticos potencialmente representan un riesgo para la sociedad, incluso mediante la creación de contenido con malas intenciones, como el uso de discursos de odio u otro lenguaje que dañe la imagen, los estados que crean narrativas falsas con actores sintéticos o la pornografía deepfake de celebridades y venganza. Algunas empresas han tomado medidas para limitar el acceso a su tecnología con códigos de ética como Synthesia * y Sonantic. El debate sobre las medidas de seguridad, como etiquetar el contenido como sintético e identificar a su creador y propietario, apenas está comenzando y probablemente seguirá sin resolverse en el futuro.
La aparición continua de una pila de inteligencia artificial china separada
China ha seguido desarrollándose como una potencia mundial de inteligencia artificial, con un enorme mercado que es el mayor productor de datos del mundo. El año pasado vio la primera proliferación real de la tecnología de consumo de inteligencia artificial china con el éxito transfronterizo occidental de TikTok, basado en uno de los mejores algoritmos de recomendación de inteligencia artificial jamás creados.
Con el mandato del gobierno chino en 2017 para la supremacía de la IA para 2030 y con el apoyo financiero en forma de miles de millones de dólares en fondos para apoyar la investigación de IA junto con el establecimiento de 50 nuevas instituciones de IA en 2020, el ritmo del progreso ha sido rápido. Curiosamente, aunque gran parte de la infraestructura tecnológica de China todavía se basa en herramientas creadas por occidente (por ejemplo, Oracle para ERP, Salesforce para CRM), ha comenzado a surgir una pila de producción propia separada.
Los ingenieros chinos que utilizan la infraestructura occidental se enfrentan a barreras culturales y lingüísticas que dificultan la contribución a los proyectos occidentales de código abierto. Además, en el aspecto financiero, según Bloomberg , los inversores con sede en China en empresas de IA de EE. UU. De 2000 a 2020 representan solo el 2,4% de la inversión total en IA en EE. UU. La disputa de Huawei y ZTE con el gobierno de EE. UU. Aceleró la separación de las dos pilas de infraestructura. , que ya enfrentó vientos en contra de la unificación.
Con el sentimiento nacionalista en un nivel alto, la localización (国产 化 替代) para reemplazar la tecnología occidental con infraestructura de cosecha propia ha cobrado impulso. La industria de Xinchuang (信 创) está encabezada por una ola de empresas que buscan construir infraestructura localizada, desde el nivel de chip hasta la capa de aplicación. Si bien Xinchuang se ha asociado con tecnología de menor calidad y funcionalidad, en el último año, se logró un progreso claro dentro de la nube de Xinchuang (信 创 云), con lanzamientos notables que incluyen Huayun (华云), CECstack de China Electronics Cloud y Easystack (易 捷行 云).
En la capa de infraestructura, los actores de infraestructura chinos locales están comenzando a avanzar hacia las principales empresas y organizaciones administradas por el gobierno. ByteDance lanzó Volcano Engine dirigido a terceros en China, basado en la infraestructura desarrollada para sus productos de consumo que ofrecen capacidades que incluyen recomendación y personalización de contenido, herramientas enfocadas en el crecimiento como pruebas A / B y monitoreo de desempeño, traducción y seguridad, además de la nube tradicional. soluciones de hospedaje. Inspur Group presta servicios al 56% de las empresas estatales nacionales y al 31% de las 500 principales empresas de China, mientras que Wuhan Dameng se utiliza ampliamente en múltiples sectores. Otros ejemplos de infraestructura propia incluyen PolarDB de Alibaba, GaussDB de Huawei, TBase de Tencent, TiDB de PingCAP, Boray Data y TDengine de Taos Data.
En cuanto a la investigación, en abril, Huawei presentó el PanGu-α mencionado anteriormente, un modelo de lenguaje preentrenado de 200 mil millones de parámetros entrenado en 1,1 TB de un texto chino de una variedad de dominios. Esto se eclipsó rápidamente cuando la Academia de Inteligencia Artificial de Beijing (BAAI) anunció el lanzamiento de Wu Dao 2.0 en junio. Wu Dao 2.0 es una IA multimodal que tiene 1,75 billones de parámetros, 10 veces más que GPT-3, lo que lo convierte en el sistema de lenguaje de IA más grande hasta la fecha. Sus capacidades incluyen el manejo de NLP y el reconocimiento de imágenes, además de generar medios escritos en chino tradicional, predecir estructuras 3D de proteínas como AlphaFold y más. El entrenamiento de modelos también se manejó a través de la infraestructura desarrollada en China: para entrenar a Wu Dao rápidamente (la versión 1.0 solo se lanzó en marzo), los investigadores de BAAI construyeron FastMoE,
Vea nuestra charla junto a la chimenea con Chip Huyen para obtener más información sobre el estado de la inteligencia artificial y la infraestructura de China.
[Nota: una versión de esta historia se publicó originalmente en el sitio web del autor].
Matt Turck es un VC en FirstMark, donde se enfoca en SaaS, nube, datos, ML / AI e inversiones en infraestructura. Matt también organiza Data Driven NYC, la comunidad de datos más grande de EE. UU.
Esta historia apareció originalmente en Mattturck.com . Copyright 2021
Turck, M. (15 de octubre de 2021). El aprendizaje automático, la inteligencia artificial y el panorama de datos de 2021. Recuperado 18 de octubre de 2021, de https://venturebeat.com/2021/10/16/the-2021-machine-learning-ai-and-data-landscape/