

Si los asistentes personales no tienen una base de datos específica que cubra un determinado acento regional les resulta difícil entender las instrucciones que los habitantes de esa zona les dan.
Como nos ocurre a las personas cuando aprendemos un idioma –a veces incluso en nuestra propia lengua materna–, si el acento de nuestro interlocutor es muy diferente al que estamos acostumbrados, nos cuesta comprender lo que dice. En los asistentes personales, guiados por inteligencia artificial, esto es más drástico todavía.
El reconocimiento de voz de Amazon Alexa, Google Assistant, Siri o Microsoft Cortana se fundamenta en bases de datos, a las que los programas acceden según unos algoritmos sofisticados, que permiten cierto margen de arbitrariedad. Una vez se sobrepasa este límite sobreviene la incomprensión. A este momento de colapso le sigue la ejecución de un comando que no hemos pedido y solo así sabemos que en realidad el programa no ha entendido nuestra instrucción.
El reconocimiento de voz cada vez funciona de forma más sofisticada, con menos fallos y mayor precisión, pero sigue teniendo una asignatura pendiente en los acentos. No solo tiene un escollo en los de diferentes regiones, también lo tiene en la particular forma de hablar de cada persona.
Y es que los asistentes personales tienen un modelo de reconocimiento de voz que tiende a la neutralidad. Toman como referencia el acento más neutral, con menos excepciones, o más mayoritario. A partir de ahí tratan de entender lo que dicen los usuarios. Con el paso del tiempo se han ido agregando nuevos modelos, bases de datos que contemplan las particularidades de un determinado acento. Aunque a Alexa, Assistant y al resto aún les queda trabajo por hacer para entender a todos de forma más o menos equilibrada.
En un estudio encargado por The Washington Post, Alexa y Assistant entendían de forma desigual los distintos acentos de Estados Unidos. Aquellos de la costa Oeste son los que mejor entienden el asistente de Google, con una mejora del 3% en la precisión. No es difícil ver por qué. La sede de la compañía está en Silicon Valley y al desarrollarse el programa en la costa Oeste es allí donde más se prueba, con lo que conserva ese sesgo una vez en el mercado.
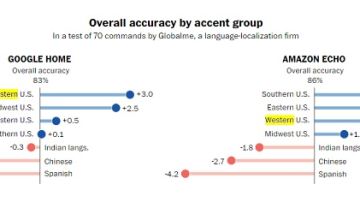
El reconocimiento de voz aprende en función de la base de datos que se introduzca y con arreglo al uso que se le dé. Así que además de las pruebas también ha podido influir el hecho de que ha habido más early adopters en la tecnológica zona de la bahía de San Francisco, con la consecuencia de que la inteligencia artificial ha ido puliéndose para este acento.
En cambio, para Amazon Alexa la mayor precisión se obtiene en con el acento sureño de Estados Unidos, un 3,1% más que la media. En esto influyó la introducción a principios de año de un modelo específico en Alexa para los hablantes del sur del país.
El estudio también apunta, en contraposición, que aquellos en Estados Unidos cuya lengua materna es el español tienen el acento más incomprensible al hablar inglés para Assistant y Alexa, un 3,2% y un 4,2% respectivamente menos que la media.
Fuente: Tecnoxplora